
Data Lake
ระบบโครงสร้างพื้นฐานข้อมูล Data Lake
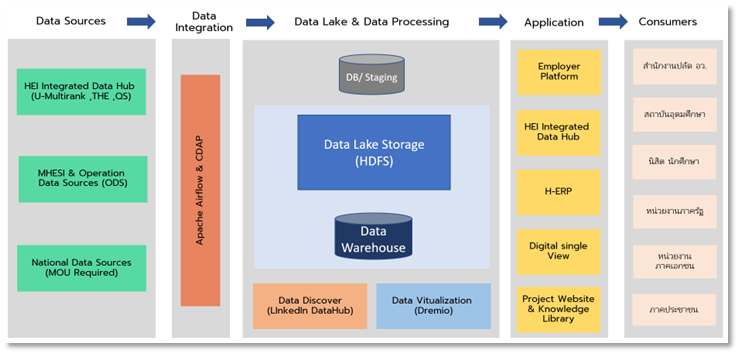
ระบบ Data Lake เป็นส่วนประกอบสำคัญของโครงการเนื่องจากเป็นองค์ประกอบหลักที่ทำหน้าที่รวบรวม จัดเก็บ และประมวลผลข้อมูลเพื่อตอบสนองการใช้ประโยชน์ซึ่งคณะทำงานได้เลือกใช้ชุดซอฟต์แวร์แบบไม่มีค่าลิขสิทธิ์รายปีผูกมัด สป.กระทรวงการอุดมศึกษาฯ ในอนาคต สามารถเพิ่มเติมและขยายผลรองรับกิจกรรมการใช้ประโยชน์จากข้อมูลได้ในอนาคต
ระบบข้อมูล (Data Lake) จะถูกพัฒนาและติดตั้งบน Big Data Platform ซึ่งใช้ซอฟต์แวร์และองค์ประกอบของ Apache Hadoop โดยจะมีการเชื่อมโยงไปยังแหล่งข้อมูล (operational data sources) ผ่านเครื่องมือเชื่อมต่อข้อมูล (data integration) สำหรับนำเข้ามูลเข้าสู่การประมวลผลข้อมูล (data processing) การสืบค้นข้อมูล (data discovery) การจัดทำข้อมูลเสมือน (data virtualization) และรวมถึงการนำไปใช้ประโยชน์ อาทิ (1) การพัฒนาต่อยอดไปเป็นแอปพลิเคชันเพื่อบริการแก่ผู้เกี่ยวข้องทั้งในและนอกสป.กระทรวงการอุดมศึกษาฯ (application) (2) การต่อยอดการวิเคราะห์ข้อมูลด้วย BI (business intelligence) (3) การต่อยอดด้วยการนำไปจัดเก็บไว้ในคลังข้อมูล (data warehouse) และ (4) การต่อยอดสำหรับปฏิบัติการปัญญาประดิษฐ์ (artificial- intelligence operations หรือ AIOps) และการพัฒนาการเรียนรู้ด้วยเครื่อง (machine-learning operations หรือ MLOps)
บริการสืบค้นข้อมูล (Data Discovery)
เมื่อข้อมูลถูกจัดเก็บในระบบ data lake หรือถูกนำไปใช้ประโยชน์และนับวันอาจมีปริมาณข้อมูลมากขึ้น มีอาจมีความหลากหลายในมิติ มีความซับซ้อน และบริบทที่แตกต่างกันออกไป คณะทำงานจึงเล็งเห็นและมีแนวคิดเสนอการใช้ประโยชน์จากข้อมูลในลักษณะ End-to-End จึงได้สืบค้นคุณลักษณะเครื่องมือที่ตอบสนองต่อปฏิบัติการข้อมูล (DataOps) ของกระทรวงการอุดมศึกษาฯ และกำหนดให้ผู้ใช้งานข้อมูล (data consumer) สามารถเข้าสืบค้นข้อมูลเมทาดาต้าจาก Data Lake ด้วยโปรแกรม Data Discovery ซึ่งจะอำนวยความสะดวกให้ผู้ใช้งานหรือนักพัฒนาระบบอื่นที่ต้องการแสวงหาข้อมูลเพื่อนำไปใช้ในการพัฒนาระบบตนเอง สามารถบริการตนเอง (self-service) และขอสิทธิ์การเข้าได้ตามความต้องการ
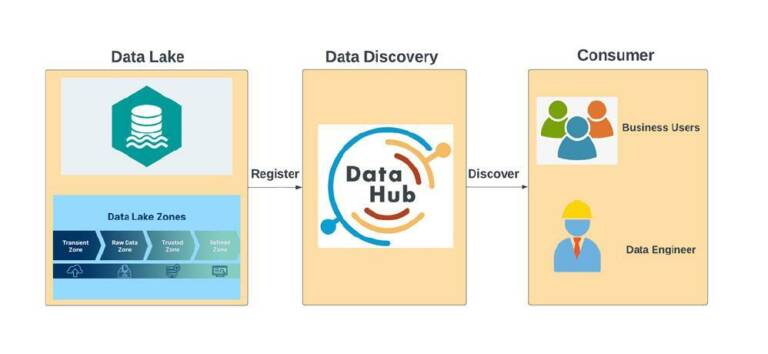
บริการข้อมูลเสมือน (Data Vrtualization)
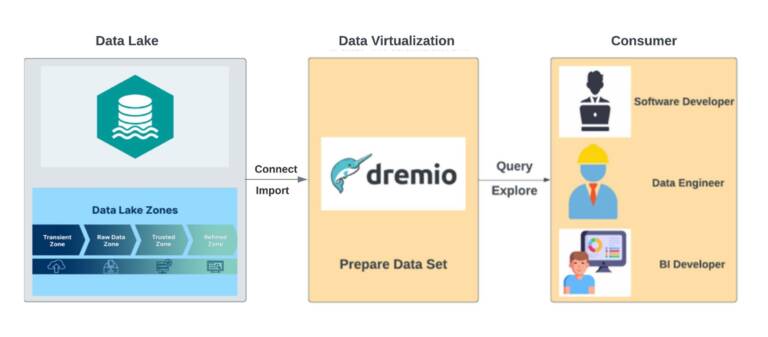
บริการข้อมูลเสมือน (data virtualization) ซึ่งจะเชื่อมต่อข้อมูลจาก data lake storage และจัดทำข้อมูลไว้เพื่อบริการแก่ผู้เกี่ยวข้องให้พร้อมใช้งาน โดยใช้โปรแกรม Dremio ที่เป็นเครื่องมือช่วยในการประมวลผลข้อมูล โดยทำหน้าที่เป็น Query Engine ซึ่งจะเชื่อมต่อข้อมูลไปยัง Data Lake และจัดทําข้อมูล (Date Set) ไว้เพื่อบริการแก่ผู้เกี่ยวข้องให้พร้อมนำไปใช้งาน
วัตถุประสงค์ของระบบ Data Lake
- เพื่อบริการการสืบค้นข้อมูล (data discovery) สามารถสืบค้น เข้าถึง และทำความเข้าใจได้โดยง่าย เอื้ออำนวยต่อผู้พัฒนาระบบในส่วนอื่นของโครงการ
- พัฒนาข้อมูลเสมือน (data virtualization) ซึ่งจะเชื่อมต่อข้อมูลไปยัง data lake storage และจัดทำข้อมูลไว้เพื่อบริการแก่ผู้เกี่ยวข้องให้พร้อมใช้งาน
คุณสมบัติที่สำคัญของระบบ (Key Features)
- เชื่อมต่อกับแหล่งข้อมูลทั้งภายใน และภายนอก อว.
- ประมวลผลข้อมูลที่มีความต้องการ สำหรับการวิเคราะห์และแสดงผลในลักษณะ Descriptive Analytics มาทำการสรุปยอดและรวมผลข้อมูลตามโจทย์ที่กำหนดและเก็บสะสมในรูปแบบที่พร้อมใช้งาน
- รองรับการให้บริการข้อมูลแก่ระบบภายในโครงการ Reinventing และผู้ใช้งานภายใน อว.
ระบบ Data Lake ได้มีการใช้ข้อมูลจากฐานข้อมูล สป.อว. และหน่วยงานภายนอกดังต่อไปนี้
ฐานข้อมูลของระบบ Data Lake ประกอบไปด้วย
- ข้อมูลประสิทธิภาพและศักยภาพจากระบบ UCLAS
- ข้อมูลการส่งเสริมของกระทรวงอุดมศึกษา วิทยาศาสตร์ วิจัยและนวัตกรรม
- ข้อมูลบุคลากรและมิติการวิเคราะห์ที่มีการใช้งานเชิงนโยบาย
- ข้อมูลผู้เรียนและการผลิตบัณฑิต
- ข้อมูลการสำรวจด้าน Employer Reputation
- ข้อมูลการสอน การวิจัย และวิทยานิพนธ์ (สำหรับ teaching and research insight)
- ข้อมูลงบประมาณและเงินทุน
- ข้อมูลการวิจัยและความสอดคล้องอุตสาหกรรม
- ข้อมูลจากองค์กรระหว่างประเทศสำหรับ Thai HEI Outlook และ SDGs
- ข้อมูลหลักสูตรการเรียนการสอน
- ข้อมูลจาก Social Platform
- ข้อมูลจาก Media Monitoring และ Visibility ของมหาวิทยาลัยทั้งในและต่างประเทศ
- ข้อมูลการผลิตนวัตกรรมและ Startup
- ข้อมูลอื่นที่เกี่ยวข้องตามมติคณะกรรมการ
